PDF continues to be a popular document publishing format because users see them as the digital equivalent of paper documents. Unlike websites, often what you see on the PDF will be exactly how it will be printed on a physical page, with the added benefits of easily distributable files and near-ubiquitous support of software able to read this format on almost any standard digital device.
However, when information, especially structured data, is contained within a PDF document and one wishes to extract that content, the format becomes quite difficult for developers to interact with.
In this post, I outline a real-world example of parsing a large PDF file that contains repeated tables of data. I show how the raw text can be extracted and then detail much more low-level control over the text characters positioned within the pages. I also touch on the actual mechanics of working through a problem like this - using tools like Excel to explore and analyze both the nature of the PDF, as well as the vagaries of the data itself.
Breeders’ Cup Betting Challenge
The Breeders’ Cup Betting Challenge (BCBC) is an annual $10,000 buy-in, live-money horse racing handicapping tournament tied to the two-day, 14-race $30 million Breeders’ Cup World Championships event. In 2018, 391 entries competed for the $1 million prize pool. It would also be the first time that the Breeders’ Cup had taken the decision to publish all the players’ tournament wagers placed at the conclusion of the event.
A few days after the competition ended, a 900+ page PDF file was posted to the Breeders’ Cup website containing a breakdown of all of the wagers placed by each player.
Intrigued by this rare example of transparency into how professional and advanced horse racing tournament players approached this format, I decided to see if I could extricate the data within to conduct some analysis for educational and entertainment purposes.
Apache PDFBox
The Apache PDFBox library is an open-source Java tool for interacting with PDF documents.
It allows the “creation of new PDF documents, manipulation of existing documents and the ability to extract content from documents”.
I’ve found that even for PDFs that turn off the ability to copy text from the document, PDFBox can still extract the content.
(1 of 3) Basic: outputting the raw text line-by-line
When attempting to parse a PDF generally you first want to just output the raw text to examine if there are any obvious patterns that can be used.
A File can be read by PDFBox as a PDF document by using PDDocument.load().
Once the file is a PDDocument, PDFTextStripper’s writeText() method can be used to strip just the text (without any of the formatting and such) and write it to a file:
class BCBCParser extends PDFTextStripper {
@Override
public void parse(File source) {
try (PDDocument document = PDDocument.load(source)) {
// The order of the text tokens in a PDF file may not be in the same as they appear
// visually on the screen, so tell PDFBox to sort by text position
setSortByPosition(true);
try (BufferedWriter writer = Files.newBufferedWriter(Paths.get("bcbc.txt"), UTF_8)) {
// This will take a PDDocument and write the text of that document to the writer.
writeText(document, writer);
}
} catch (InvalidPasswordException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
This resulted in output like the following in bcbc.txt:
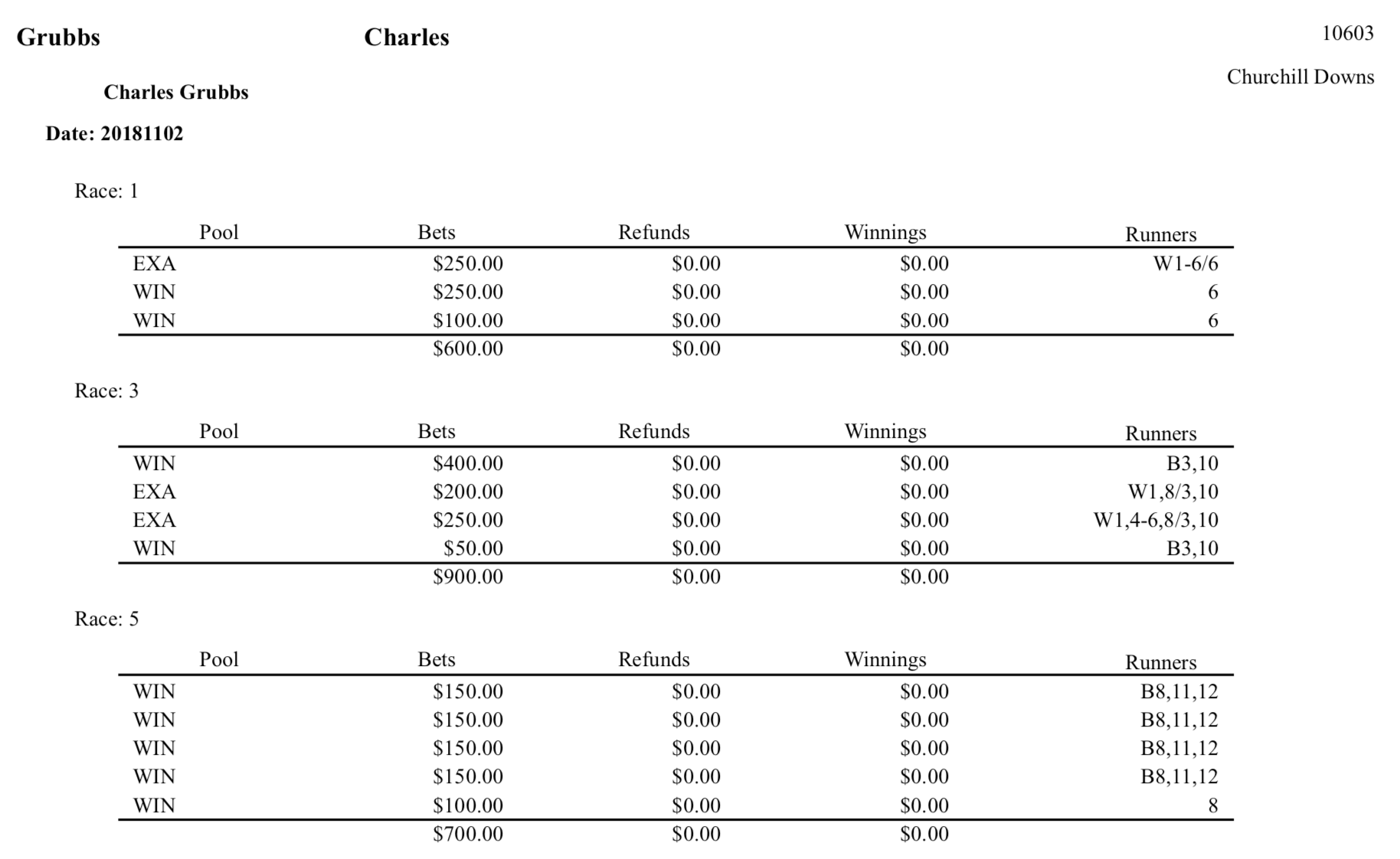
Grubbs Charles 10603
Churchill Downs
Charles Grubbs
Date: 20181102
Race: 1
Pool Bets Refunds Winnings Runners
EXA $250.00 $0.00 $0.00 W1-6/6
WIN $250.00 $0.00 $0.00 6
WIN $100.00 $0.00 $0.00 6
$600.00 $0.00 $0.00
Race: 3
Pool Bets Refunds Winnings Runners
WIN $400.00 $0.00 $0.00 B3,10
EXA $200.00 $0.00 $0.00 W1,8/3,10
EXA $250.00 $0.00 $0.00 W1,4-6,8/3,10
WIN $50.00 $0.00 $0.00 B3,10
$900.00 $0.00 $0.00
Race: 5
Pool Bets Refunds Winnings Runners
WIN $150.00 $0.00 $0.00 B8,11,12
WIN $150.00 $0.00 $0.00 B8,11,12
WIN $150.00 $0.00 $0.00 B8,11,12
WIN $150.00 $0.00 $0.00 B8,11,12
WIN $100.00 $0.00 $0.00 8
$700.00 $0.00 $0.00
Race: 6
Pool Bets Refunds Winnings Runners
WIN $200.00 $0.00 $0.00 14
TRI $240.00 $0.00 $11,154.00 W6/14/1-14
TRI $60.00 $0.00 $0.00 W6/1-14/14
TRI $60.00 $0.00 $0.00 W6/1-14/14
...
$934.00 $0.00 $4,136.00
Race: 9
Pool Bets Refunds Winnings Runners
TRI $240.00 $0.00 $0.00 W6,9/2,4-6,9,10,12,13/2,
13
$240.00 $0.00 $0.00
Race: 10
...
2-Day Totals $53,420.00 $0.00 $132,250.00
Penalty Amount: $0.00 Final Score: 86,330.00
Engler Monte 900000778
Twinspires
Monte Engler
Date: 20181102
Race: 4
Pool Bets Refunds Winnings Runners
DOUBLE $50.00 $0.00 $0.00 2/4
DOUBLE $40.00 $0.00 $0.00 W3/1,4
$90.00 $0.00 $0.00
Race: 6
Pool Bets Refunds Winnings Runners
TRIFECTA $360.00 $0.00 $0.00 W6/2,11,12/1-14
TRIFECTA $120.00 $0.00 $0.00 W1,6/1-14/1,6
DOUBLE $150.00 $0.00 $0.00 W1,11,12/1-10
Immediately, it could be seen that there are aspects of the output that could prove fruitful:
- there are repeated text values (e.g. “Final Score: “) that could be used to mark where sections began and ended e.g. the player’s name, ID and home track always follow that line.
- as it was a two-day event, the exact race that the wagers were for could be figured out by combining for the “Date: YYYYMMDD” and “Race: N” patterns.
- some of the data is derived e.g. the bets/refunds/winnings totals-per-day and the Final Score; I generally prefer to parse just the minimum data and calculate those independently.
However, there were some things of concern that were noted:
- For wagers with many combinations, the textual representation of the bet often wrapped to the next line - great care would have to be taken to detect and handle that.
- Oddly, a mix of bet type keys was being used. For example for Trifecta bets, some players had “TRI”, others had “TRIFECTA”. Some people seems to have made bets that were actually against the rules (yet possibly not detected by the tournament software). Clearly some data sanitation would be required. It also means that you can’t always rely on the consistency of specific “special” values but rather try to be rules- and/or pattern-based instead.
(2 of 3) Basic: parsing the raw text word-by-word
The BCBC table data is simple enough however to figure most of this out with basic rules and some regexes.
The following is the main parser for the BCBC PDF files (the entire project is available on GitHub).
It builds a list of BCBCEntry objects (corresponding to tournament players), each of which contain a list of the parsed bets.
The overridden writeText() method triggers a variety of calls to other methods that can also be overridden to further control the parsing of the PDDocument, including writePage(), writeCharacters(TextPosition text), and writeString(String text, List<TextPosition> textPositions) among others.
The latter is leveraged below to capture specific words that are expected, along with setting various marker booleans that instruct subsequent iterations to extract the desired information. Some pre-processing and sanitation is done by the BCBCEntry and Bet classes (see GitHub for the details):
public class BCBCParser extends PDFTextStripper implements Parser<List<BCBCEntry>, File> {
static final Logger LOGGER = LoggerFactory.getLogger(BCBCParser.class);
// regex to match bets e.g. EX, TRI, DD, WIN
private static final Pattern BET_TYPE = Pattern.compile("^([A-Z-])+$");
private final BCBCConfig config;
private List<String> bcbcEntryRelatedText;
private List<BCBCEntry> bcbcEntries;
/**
* Instantiate a new PDFTextStripper object.
*
* @throws IOException If there is an error loading the properties.
*/
public BCBCParser(BCBCConfig config) throws IOException {
super();
this.config = config;
bcbcEntryRelatedText = new ArrayList<>();
bcbcEntries = new ArrayList<>();
// see https://pdfbox.apache.org/2.0/getting-started.html
System.setProperty("sun.java2d.cmm", "sun.java2d.cmm.kcms.KcmsServiceProvider");
}
@Override
public List<BCBCEntry> parse(File bcbcResults) {
try (PDDocument bcbcResultsPdf = PDDocument.load(bcbcResults)) {
setSortByPosition(true);
try (Writer devNullWriter = new OutputStreamWriter(new OutputStream() {
@Override
public void write(int b) {
// discard everything
}
}, UTF_8)) {
// this will end up calling #writeString() below with the text of each line
// each line of text can then be examined in the context of the text already
// parsed, so can figure out if the text is related to the player or the bet etc
// the line of text itself will be pulled apart to extract the actual bets
writeText(bcbcResultsPdf, devNullWriter);
// at this point, all the players' start-end line indexes have been saved
}
} catch (InvalidPasswordException e) {
LOGGER.error("PDF Password incorrect", e);
} catch (IOException e) {
LOGGER.error("Error parsing PDF", e);
}
bcbcEntries.forEach(bcbcEntry ->
bcbcEntry.getBets().addAll(createBetsForEntry(config, bcbcEntry)));
return bcbcEntries;
}
// triggered during stripper.writeText() execution above (by the private stripper.writeLine()
// method) and called for each "word" of a line processed when parsing the PDF (sometimes a word
// may actually be a single space-separated piece of text)
@Override
protected void writeString(String string, List<TextPosition> textPositions) throws IOException {
// collect all the words relevant for this entry
bcbcEntryRelatedText.add(string);
// if "Final Score" was found, then we at the end of content about this player
if (string.contains("Final Score")) {
BCBCEntry entry = new BCBCEntry(bcbcEntryRelatedText);
bcbcEntries.add(entry);
// reset
bcbcEntryRelatedText = new ArrayList<>();
}
}
// word-by-word parsing and building the data structure
private List<Bet> createBetsForEntry(BCBCConfig config, BCBCEntry entry) {
List<Bet> bets = new ArrayList<>();
boolean day2Found = false;
boolean betTypeFound = false;
boolean activeBetComplete = false;
boolean penaltyAmountFound = false;
int race = 0;
Bet.Builder betBuilder = new Bet.Builder();
for (String word : entry.getPlayerText()) {
// if it's Saturday's date, then Friday bets must be done
if (word.equals("Date: " + config.getDay2Date())) {
day2Found = true;
continue; // go to the next word (it should be the race number)
}
// track the race these bets were for
if (word.startsWith("Race: ")) {
race = Integer.parseInt(word.substring(word.lastIndexOf(' ') + 1));
continue; // go to the next word (it should be the start of the betBuilder table)
}
// update the entry with the total amount of penalties incurred
if (penaltyAmountFound) {
entry.setPenalty(word);
penaltyAmountFound = false; // reset
}
// only betBuilder types (Exacta, Trifecta etc.) are in all-caps around the
// betBuilder data
// set this market because next word/line (or two, if wrapped) will be related to
// a betBuilder
boolean betTypeDetected = BET_TYPE.matcher(word).find();
// race totals are derived summary data that aggregate the lines above it
// we don't need to parse it but it is a marker that all bets for this race have
// been parsed
boolean raceTotalsSummaryLineDetected = (word.split(" ").length == 3);
// first check for any bets that have not yet been fully parsed
if (betTypeFound) {
boolean completionOfActiveBetDetected =
(betTypeDetected || raceTotalsSummaryLineDetected);
// check if a betBuilder description has wrapped to the next line and update it
// if so
if (!completionOfActiveBetDetected) {
// because of trailing spaces between the "Bets", "Refunds", "Winnings", and
// "Runners" column values, this "word" contains values intended for
// multiple columns
//
// the setter handles splitting this into its respective components as well as
// handling line-wraps and inconsistent delimiters
betBuilder.compositeBetInfo(word);
}
activeBetComplete = true;
}
// build and save the bet if it is ready
if (activeBetComplete) {
// set the date and race number as they can apply to multiple bets
betBuilder.date(day2Found ? config.getDay2Date() : config.getDay1Date());
betBuilder.race(race);
bets.add(betBuilder.build());
// start clean for the next betBuilder
betBuilder = new Bet.Builder();
betTypeFound = false;
activeBetComplete = false;
}
// set the marker that a betBuilder is active (ready to be parsed)
if (betTypeDetected) {
betTypeFound = true;
betBuilder.type(word);
// go to the next word (it should be the composite betBuilder information)
}
// set a flag that the next word parsed contains the penalty amount for the entry
if (word.contains("Penalty Amount:")) {
penaltyAmountFound = true;
}
}
return bets;
}
}
I was able to validate the parsing logic by picking a player (I chose 7th-placed Allen Harberg as he was the highest placed finisher that incurred a penalty) and calculated their final score just using the individual bets they placed:
@Test
public void parse_With2018Results_FinalScoreCalculatedCorrectly() throws Exception {
File bcbcResults = new File(
getClass().getClassLoader().getResource("bcbc_2018.pdf").getFile());
List<BCBCEntry> bcbcEntries = new BCBCParser(new Config2018()).parse(bcbcResults);
// the Final Score is the starting bankroll of $7,500 plus all winnings minus all bets
// minus all penalties
double finalScore = bcbcEntries.stream()
.filter(bcbcEntry -> bcbcEntry.getUuid().equals("900000129")) // Allen Harberg
.flatMapToDouble(bcbcEntry -> DoubleStream.of(bcbcEntry.getBets().stream()
.collect(summarizingDouble(bet -> (bet.getWinnings() - bet.getBets())))
.getSum() - bcbcEntry.getPenalty() + 7500))
.findAny().getAsDouble();
Assert.assertThat(finalScore, equalTo(43025d));
}
What’s more, I was able to reuse this solution again in 2019, and even created a bar chart race visualization that simulated how the leaderboard changed race-by-race using the data extracted with this solution:
A live leaderboard visualization of the @BreedersCup Betting Challenge 2019 (#BCBC) feat. @PatCummingsTIF, @truxtonstables, @stoolpresidente and @DickJerardi among others.
— Robin Howlett (@robinhowlett) November 14, 2019
Based on a recent bar chart race demo by @mbostock using @observablehq : https://t.co/PVVPjCpNAo pic.twitter.com/OhlVROozLG
(3 of 3) Advanced: outputting each character’s metadata
While I was able to certainly use the basic output of the PDF document’s text for parsing, PDFBox enables exposing the metadata of each individual character present within the document, including:
- the X-Y coordinates of the character within the page
- the font size (even font name)
- the height and width of the printed character
- the unicode character value
By leveraging the character metadata, much more fine-grained control of the parsing can be conducted. By using the actual measurements of the positioning of the text within the PDF (for instance, inferring columns in a table and grouping the values), we can avoid regex-driven development of trying to parse the purely textual output returned above, which may be very error prone for less predicatably-structured documents.
We saw earlier that TextPosition is part of the writeString() method signature, but we did not use it above. TextPosition represents “a string and a position on the screen of those characters”.
The following variables within TextPosition can be useful for understanding the positioning, size, spacing, and unicode value:
| Variable | Description |
|---|---|
| xDirAdj | The horizontal positioning of the character within a particular page |
| yDirAdj | The vertical positioning of the character within a particular page |
| fontSize | The size of the font for this character |
| height | The visible height of the character |
| widthDirAdj | The visible width of the character |
| widthOfSpace | The measurement of the space character that applies to the character |
| unicode | The unicode value of the character |
There are others too like
xScalethat may be appropriate for your use cases. View the PDFBox documentation for more.
When comparing the various metadata values of each TextPosition instance with another, certain inferences can be made, for example:
- If the difference between the
yDirAdjvalues of two characters is greater than theheightof the characters (or some other logical value), then the characters are on different lines. - If the difference between the
xDirAdjvalues of two characters is greater than thewidthDirAdjvalue, then some form of whitespace exists between characters within the string/text (some PDFs store space characters, some do not and must be calculated). fontSizeand similar can also be used to identify superscript values.
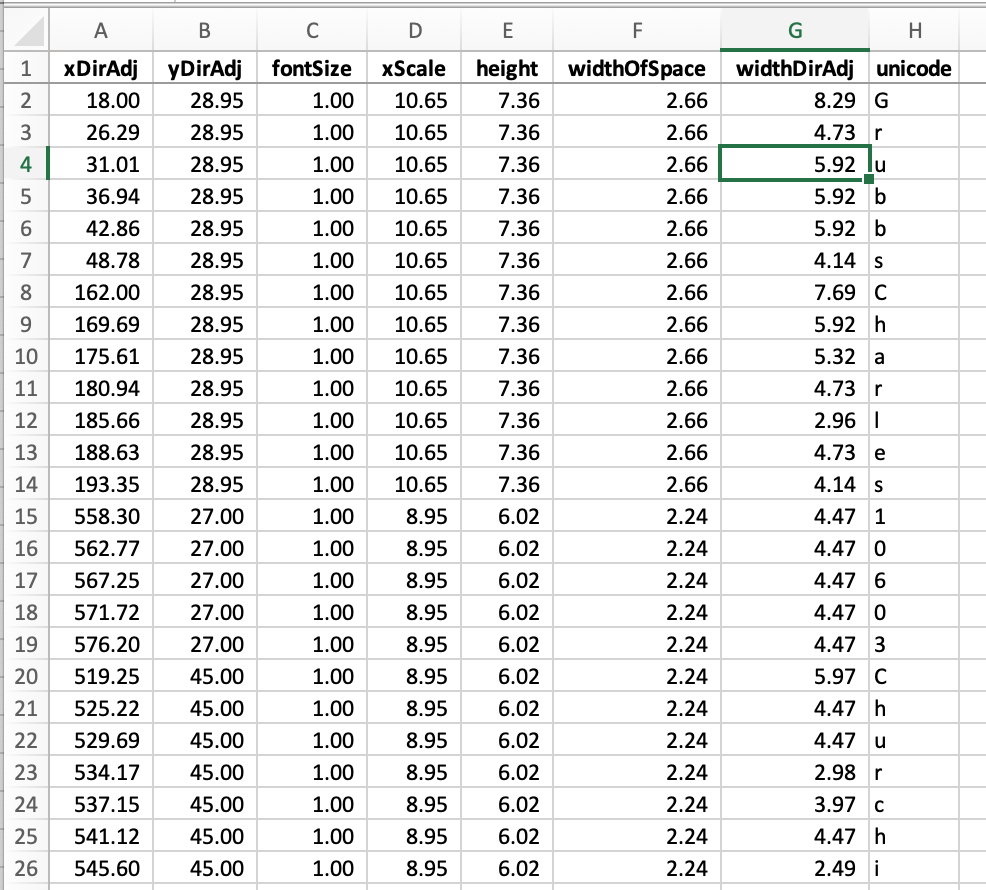
An effective way to rapidly identify patterns within the text positions of the characters in the PDF is to use a spreadsheet. To do that, we need to create a CSV where each row is character within the PDF and its relevant TextPosition metadata.
public class BCBCParser extends PDFTextStripper {
public BCBCParser() throws IOException {
super();
}
public List<TextPosition> parse(File bcbcResults) {
try (PDDocument document = PDDocument.load(bcbcResults)) {
setSortByPosition(true);
try (BufferedWriter writer = Files.newBufferedWriter(
Paths.get("text-positions.csv"), UTF_8)) {
// the first row is the header column names
String[] headers = {"xDirAdj", "yDirAdj", "fontSize", "xScale", "height",
"widthOfSpace", "widthDirAdj", "unicode"};
// use pipe as a delimiter (just as a personal preference)
writer.write(String.join("|", headers));
writer.write(System.lineSeparator());
// this will call #writeString() below with the line text and positions of each char
writeText(document, writer);
}
} catch (InvalidPasswordException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
@Override
protected void writeWordSeparator() throws IOException {
// do nothing as we don't need spaces
}
@Override
protected void writeLineSeparator() throws IOException {
// do nothing as writeString(String, List<TextPosition>) below handles the new lines
}
@Override
protected void writeString(String text, List<TextPosition> textPositions) throws IOException {
if (!text.isEmpty()) {
textPositions.forEach(textPosition -> {
try {
// call the parent's writeString(String) to write to the output writer
writeString(String.join("|",
String.valueOf(textPosition.getXDirAdj()),
String.valueOf(textPosition.getYDirAdj()),
String.valueOf(textPosition.getFontSize()),
String.valueOf(textPosition.getXScale()),
String.valueOf(textPosition.getHeight()),
String.valueOf(textPosition.getWidthOfSpace()),
String.valueOf(textPosition.getWidthDirAdj()),
textPosition.getUnicode()));
// write a line/row after each character
writeString(System.lineSeparator());
} catch (IOException e) {
e.printStackTrace();
}
});
}
}
}
This outputs to a file called text-positions.csv the following:
xDirAdj|yDirAdj|fontSize|xScale|height|widthOfSpace|widthDirAdj|unicode
18.0|28.950012|1.0|10.65|7.364475|2.6625|8.2857|G
26.2857|28.950012|1.0|10.65|7.364475|2.6625|4.7285995|r
31.0143|28.950012|1.0|10.65|7.364475|2.6625|5.9214|u
36.9357|28.950012|1.0|10.65|7.364475|2.6625|5.921398|b
42.857098|28.950012|1.0|10.65|7.364475|2.6625|5.921398|b
48.778496|28.950012|1.0|10.65|7.364475|2.6625|4.142849|s
162.0|28.950012|1.0|10.65|7.364475|2.6625|7.6893005|C
169.6893|28.950012|1.0|10.65|7.364475|2.6625|5.921402|h
175.6107|28.950012|1.0|10.65|7.364475|2.6625|5.324997|a
180.9357|28.950012|1.0|10.65|7.364475|2.6625|4.728607|r
185.6643|28.950012|1.0|10.65|7.364475|2.6625|2.9606934|l
188.625|28.950012|1.0|10.65|7.364475|2.6625|4.728607|e
193.3536|28.950012|1.0|10.65|7.364475|2.6625|4.142853|s
558.3|27.0|1.0|8.95|6.02335|2.2375|4.4749756|1
562.77496|27.0|1.0|8.95|6.02335|2.2375|4.4749756|0
567.24994|27.0|1.0|8.95|6.02335|2.2375|4.4749756|6
571.7249|27.0|1.0|8.95|6.02335|2.2375|4.4749756|0
576.1999|27.0|1.0|8.95|6.02335|2.2375|4.4749756|3
...
When opening the same file in Excel (and using Data > Text to Columns to instruct that the pipe character is a delimiter, plus adding some basic decimal formatting), we can now look at the patterns of the character metadata, to make some inferences:
Let’s look at the table that corresponds to the bets made for a particular race (see page 2 of the 2018 BCBC results PDF, race 3 of the second day):
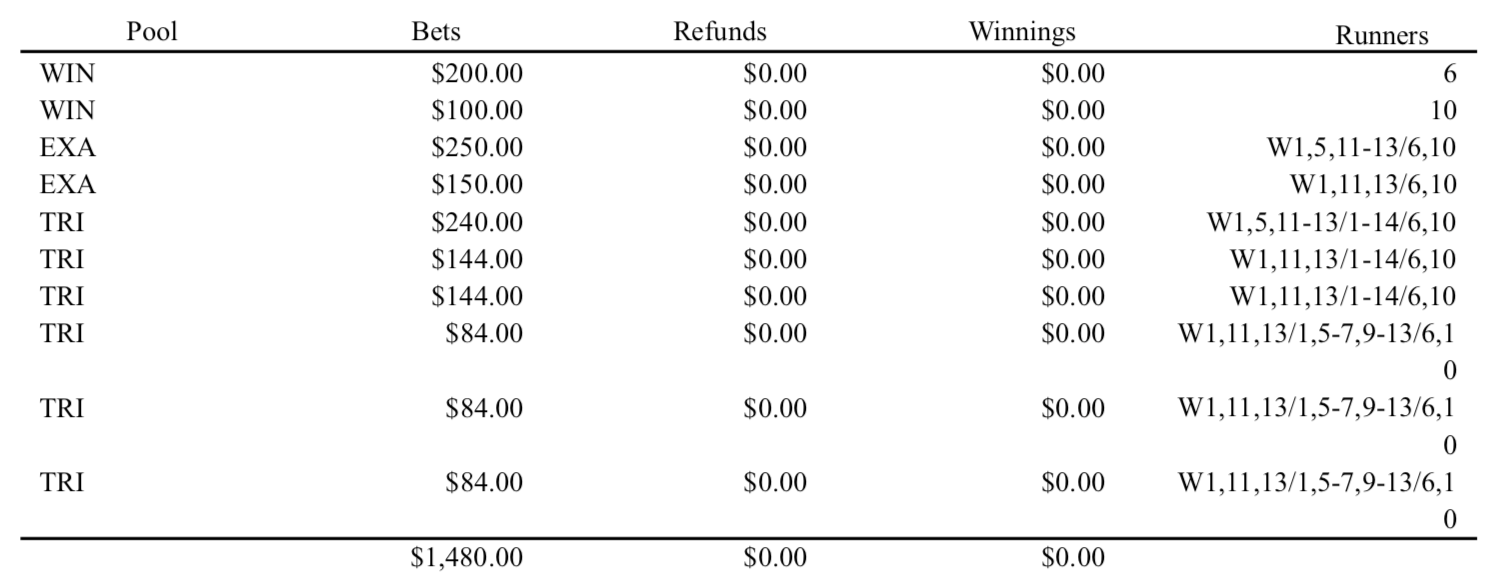
This entry is interesting because some of the bet details (under the “Runners” column) have been wrapped to the next line. Also, the “Pool” column is left-aligned, but all other columns are right-aligned.
A little scroll-and-search within Excel finds the character metadata that corresponds:
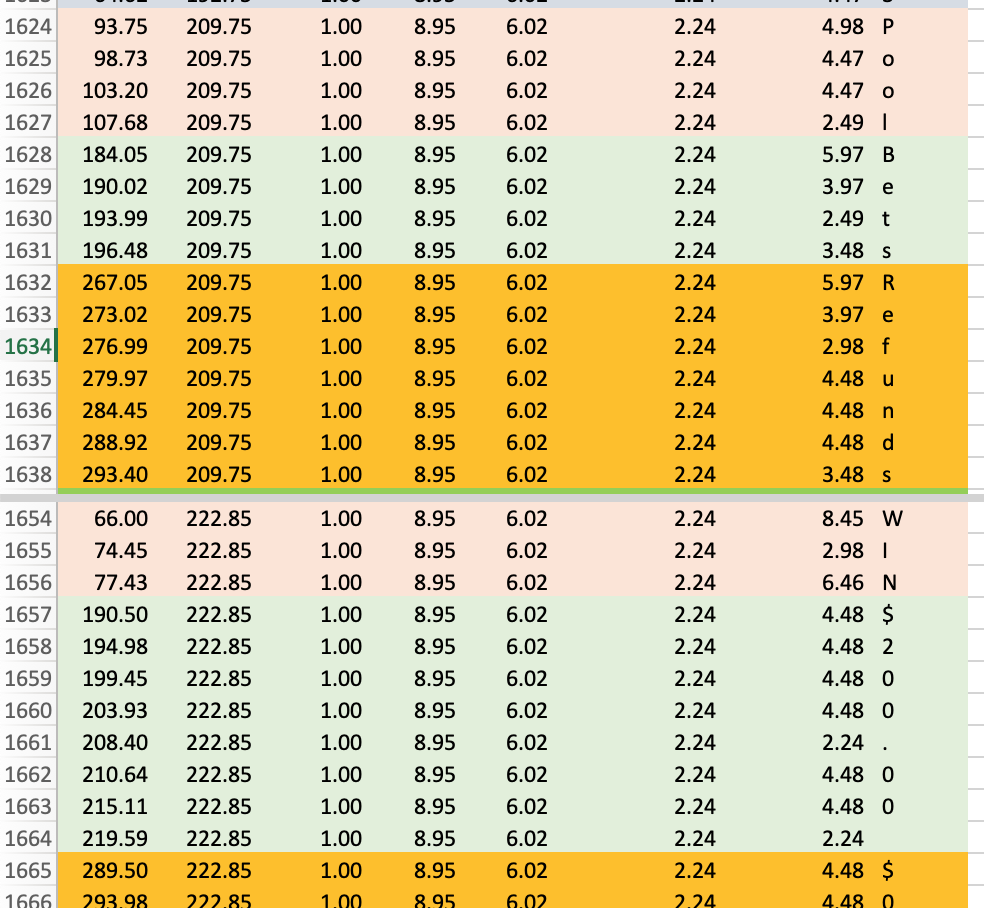
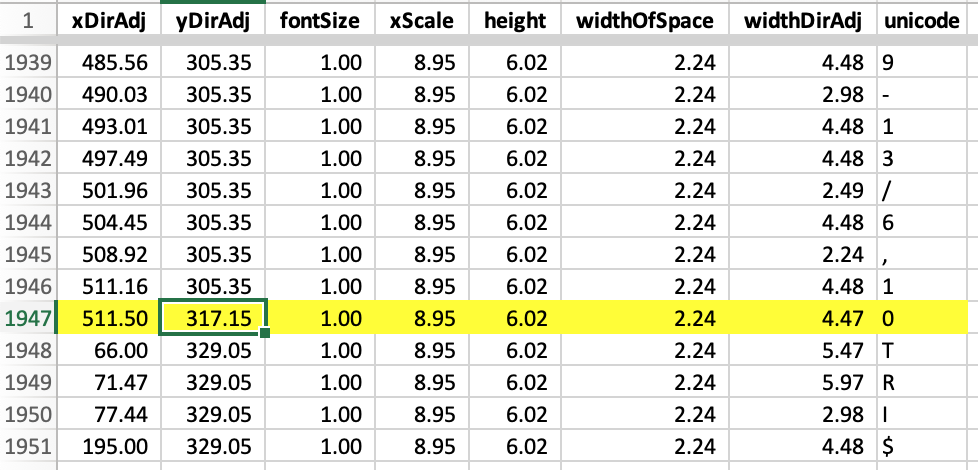
This may be hard to see but I’ve split the Excel sheet and on top highlighted the “Pool”, “Bets”, and “Refunds” column header characters, and, below, the first row character values that correspond (“WIN”, “$200,00 “, and “$0.00 “ respectively).
This allows us create rules for detecting when text has been wrapped. For example, see how the yDirAdj value of the “0” character (that was wrapped above in the PDF’s “Runners” columns) of the highlighted row is unlike the rows above and below but that it has a high xDirAdj value, indicating it is positioned to the right of the page:
Again, the BCBC PDF was simple enough in its structure to not need this level of control, but I do have experience with far more complex PDF layouts.
Consider the following PDF from Equibase for a horse racing result chart:
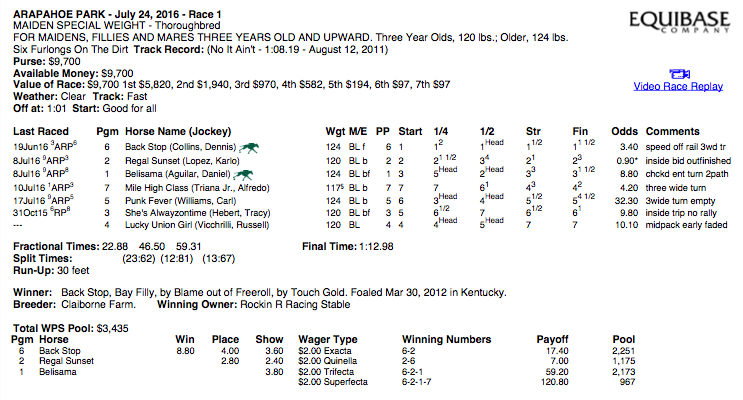
In this case, there are a variety of layouts within the document - multi-line text, multiple key-value pairs on the same line, multiple tables whose text and even number of rows and columns are fully dynamic and based on the nature of the content, superscript text, fractions, even embedded images.
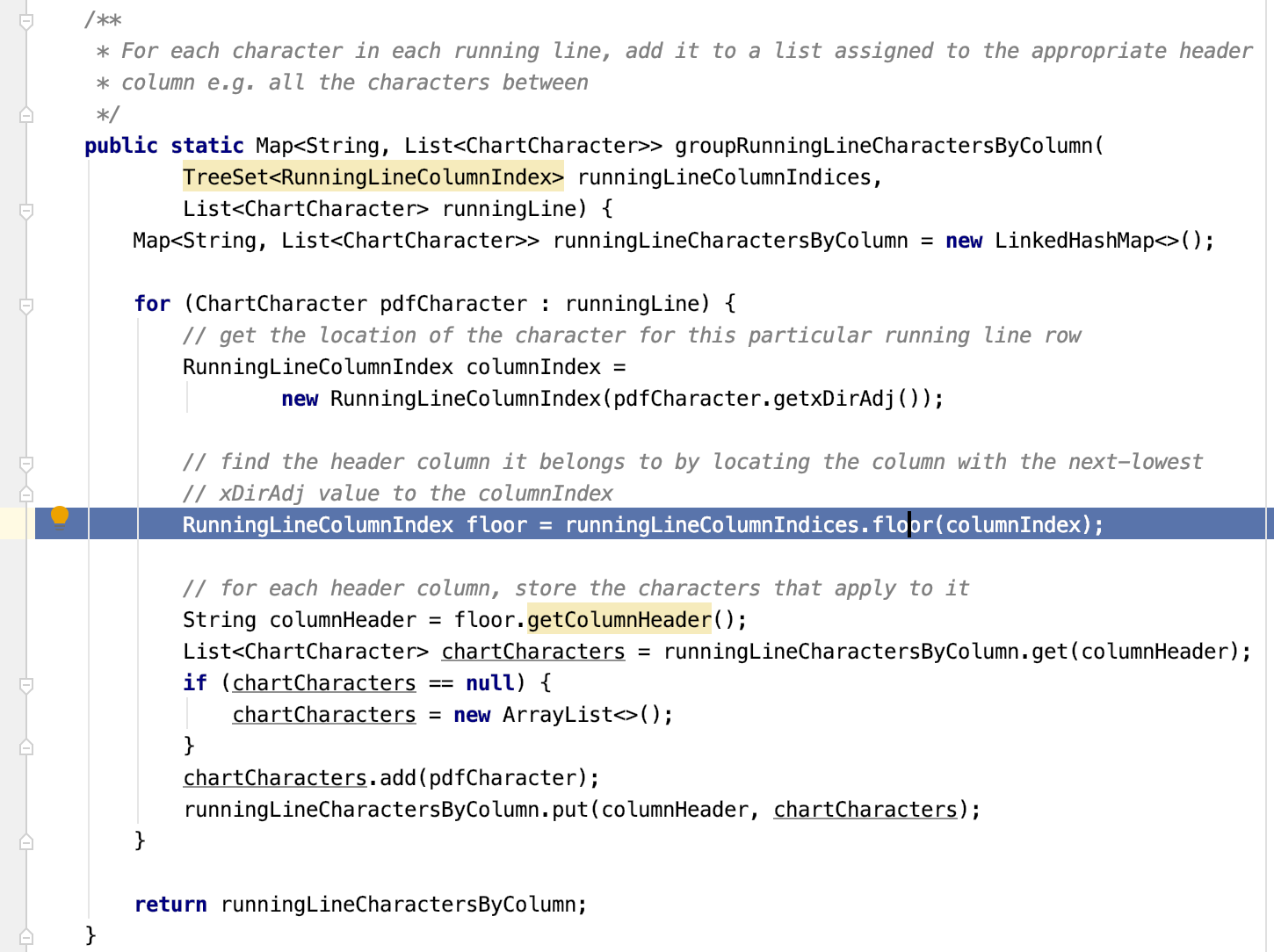
To outline just one technique, for grouping related columns of data within the table (which had semi-predicable headers), I built a TreeSet of xDirAdj and column header indices, so that for any character found within the table, I could find the nearest starting header column using the floor() method:
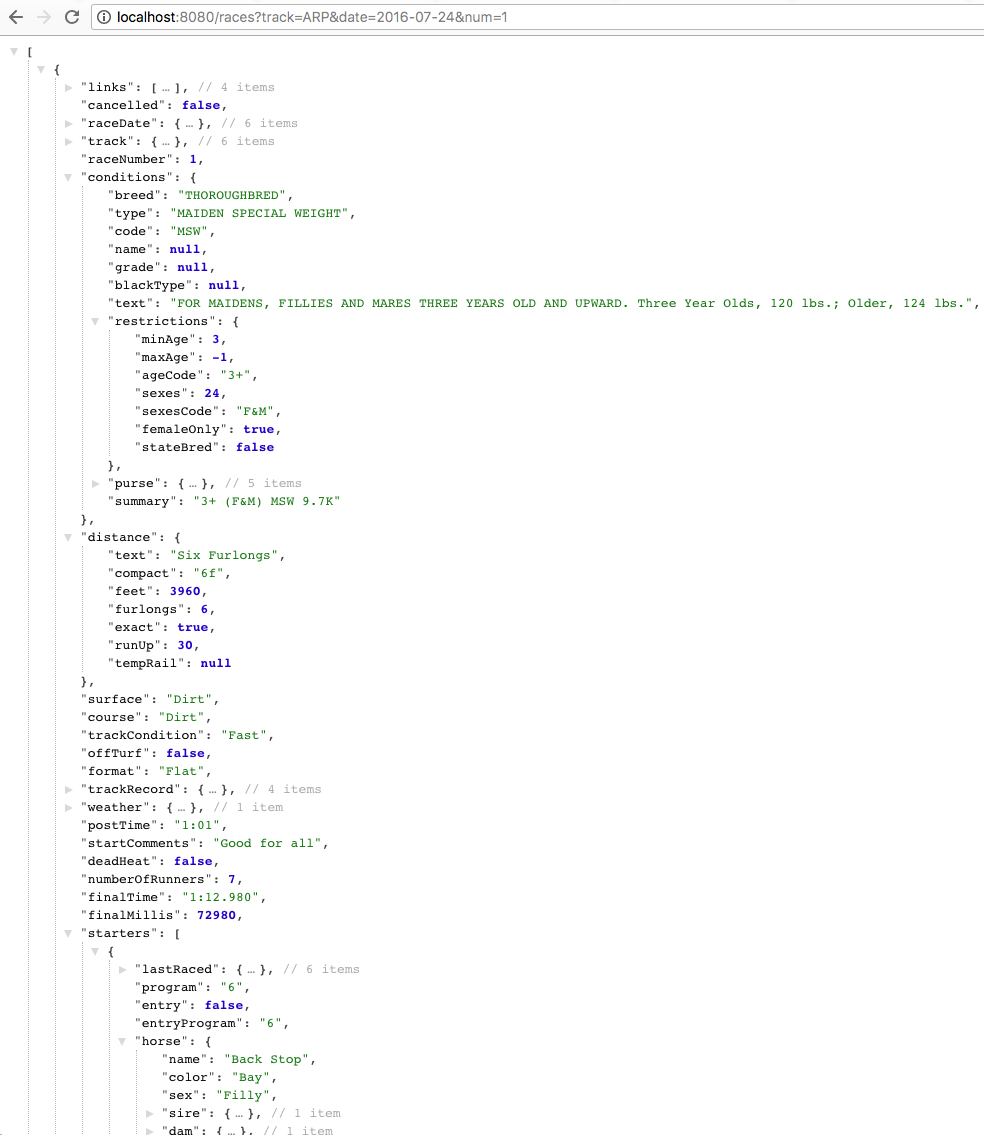
I was able to fully parse this document (and over a million others like it) into a highly-specialized domain-specific data structure that powered a variety of data-centric tools, APIs and SDKs:
Unfortunately, I ran into some issues when distributing this open-source software, but the general procedure I used was the same as what I have been describing in this post.
Between eyeballing the PDF, noting where obvious patterns exist, and potentionally building a data model using the character position metadata, you can start to construct a collection of data structures that capture the particular domain values you wish to extract from the PDF.
Comments